1、目标检测发展
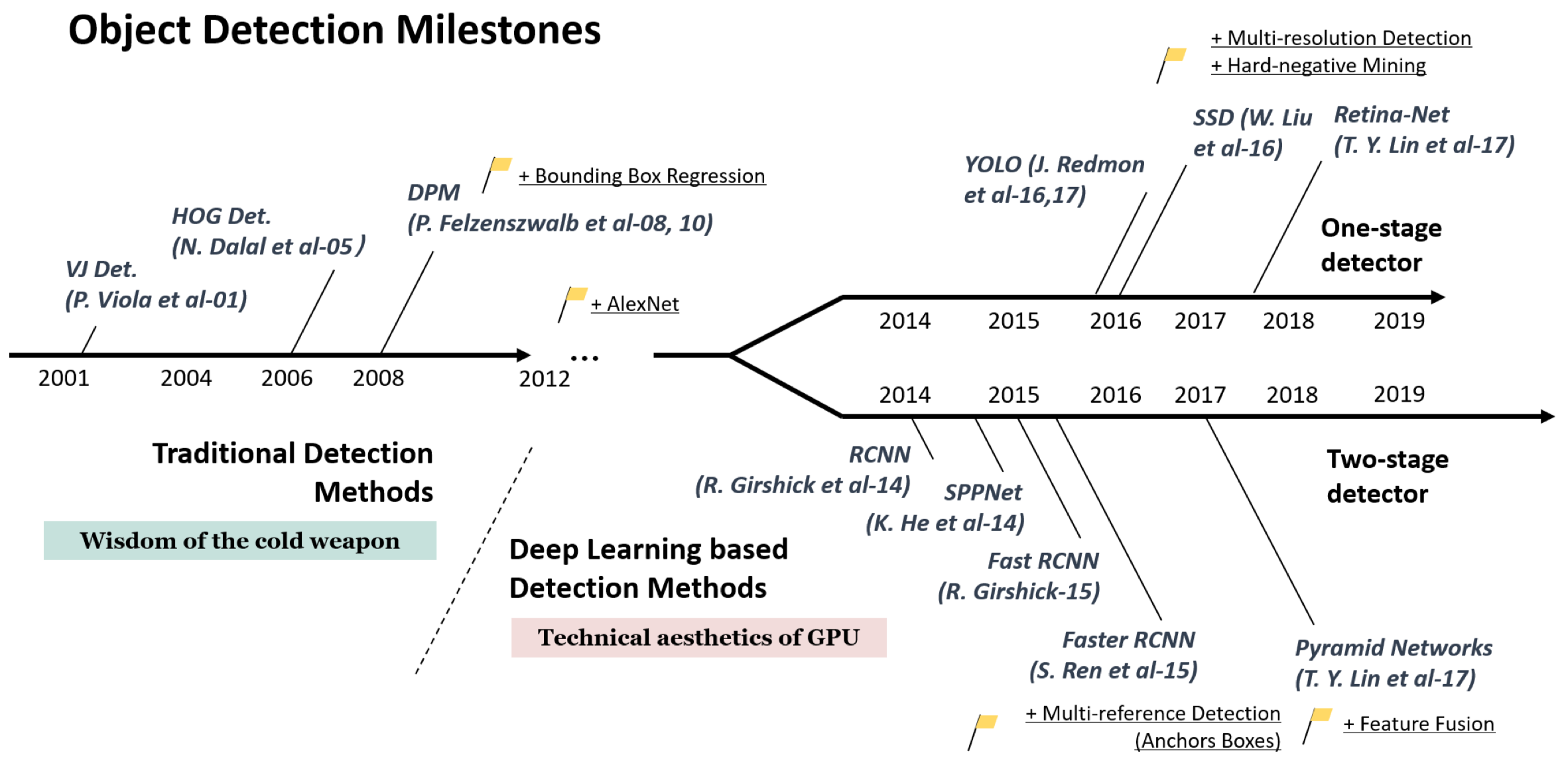
这张目标检测的Road map展示了目标检测在整个发展的过程中一些里程碑式的算法,可以看到,目标检测在卷积神经网络流行之前,主要采用传统的检测算法,其中最为重要的就是VJ检测器,用于行人检测的HOG检测器以及DPM。随着2012年AlexNet在ImageNet比赛上取得了优异的表现,卷积神经网络开始广泛应用于目标检测中。在基于CNN的目标检测中,主要发展为两类目标检测器。一类是两阶段检测算法,其中开山之作就是R-CNN,以及后续针对其优化的SPPNet,Fast R-CNN,以及Faster R-CNN。同时也有结合特征融合的FPN检测算法。另一类单阶段检测算法主要有YOLO算法系列,SSD以及引入了Focal loss的RetinaNet。
2、现有基于Anchor算法存在的问题
1. 基于Anchor算法的问题
以上基于CNN的目标检测方法在发展中,后期性能优秀的算法均采用Faster R-CNN引入的基于Anchor的候选框生成方式,这种方式的算法均为top-down结构,即先生成region proposal,然后通过提取到的region feature来refine这些proposal。基于Anchor的方法存在以下问题:
1、首先就是我们需要在“feature map”上的每一个像素点去定义很多的锚点框,假如说最后得到的“feature map”较大,整个算法当中所定义的锚点框是特别多的。当我们进行运算和操作的话,是很耗费时间与计算量的。其次,因为跟“groud truth”之间有交点的“anchor”实际上并不多,这就会造成与样本之间的一个极不均衡。
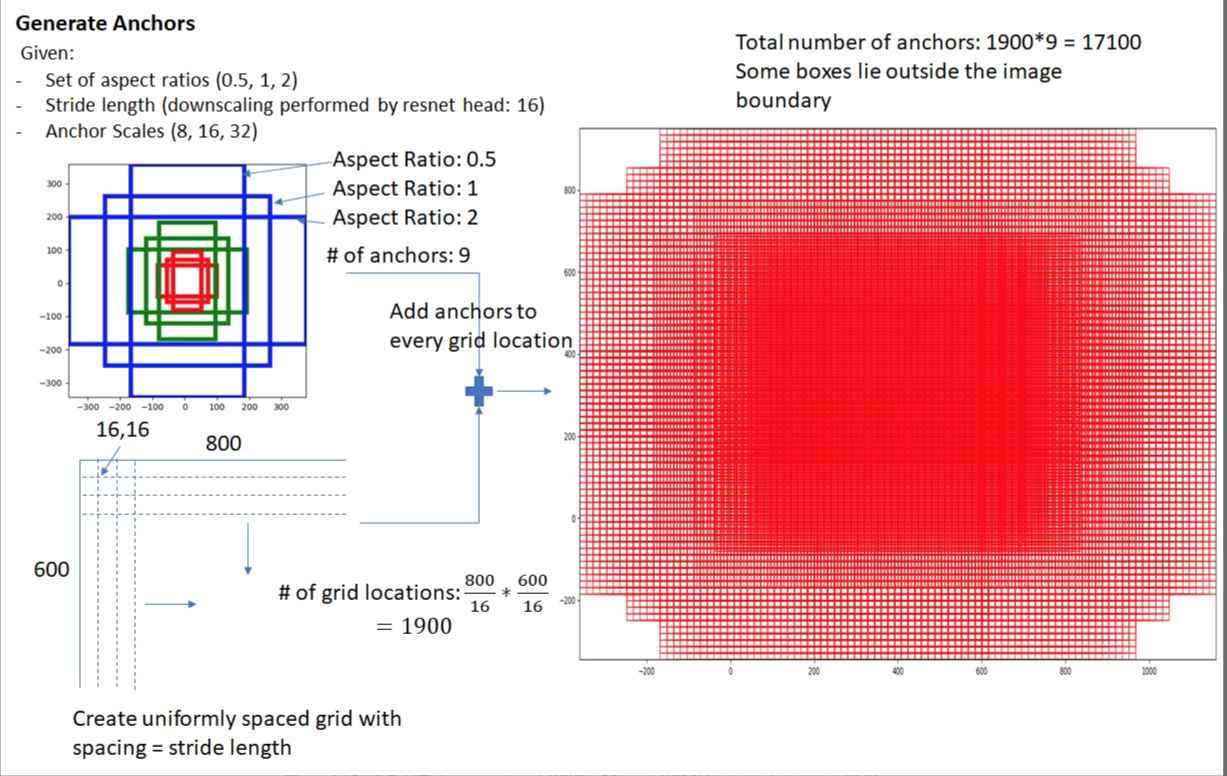
2、基于Anchor的算法会为了解决scale variation的问题,会在预设的过程中显式的枚举出不同的scale和aspect ratio,但是这样不可避免的会引入很多超参数,这些超参数的出现,会使得网络的调优变得更加困难,除了增加额外的复杂度,也会增加计算量。
2. 目标检测中Ground Truth存在的问题

使用检测框标定物体,并使用矩形框内的信息来检测目标的方式并不是非常的合理,因为矩形框内只有一部分是目标,而剩下的是背景,这些背景的语义信息会影响到检测结果,同时也会对分类结果造成影响。
3、针对以上问题的解决办法
针对anchor存在scale和aspect ratio两个超参,不容易设计的问题,产生了很多优化anchor的算法,而另一种优化方式就是Anchor-free方法,不使用Anchor来生成候选框,这种方法的产生个人认为有两个重要元素的引入:
1、首先是FPN结构,anchor free的做法相当于feature map的每个位置只能输出一个框,可以想象,如果没有FPN这种多层级的表示,如果最终的feature map downsample的倍数是8或者16,那么可能会有很多物体的中心点落在同一格子中。这样就会导致训练的时候有很大的歧义性。随着FPN的引入,不同scale的物体被分配到了不同的层级上,冲突的概率大大降低。在CenterNet中,作者还特意起计算了冲突的比例,实际不到0.1%,对于性能的影响实际上也是微乎其微的。
2、其次就是Focal loss,由于物体的中心区域是远小于其他背景区域的,整个分类的正负样本和难易样本是极不均衡的。直接训练这样的分类问题很难收敛到一个满意的结果。这样的问题其实在传统的one stage detector中同样存在,解决方案就是OHEM或者focal loss这样的加权办法。实测中,focal loss的结果会更好一些,所以focal loss也基本上被所有这类的方法所采用。
4、CenterNet
1、特点
- CenterNet的bounding box仅仅会出现在当前目标的位置处而不是整张图上,可以看作是一个形状不可知的Anchor,不需要设置阈值来筛选出positive anchor和negtive anchor,也不需要区分这个anchor是物体还是背景,因为每个目标只对应一个bounding box,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选
- CenterNet的输出分辨率的下采样因子是4,与其他目标检测框架对比来说非常小(Mask-Rcnn最小为16、SSD为最小为16),这也消除了对于多种Anchor的需要
2、整体网络结构
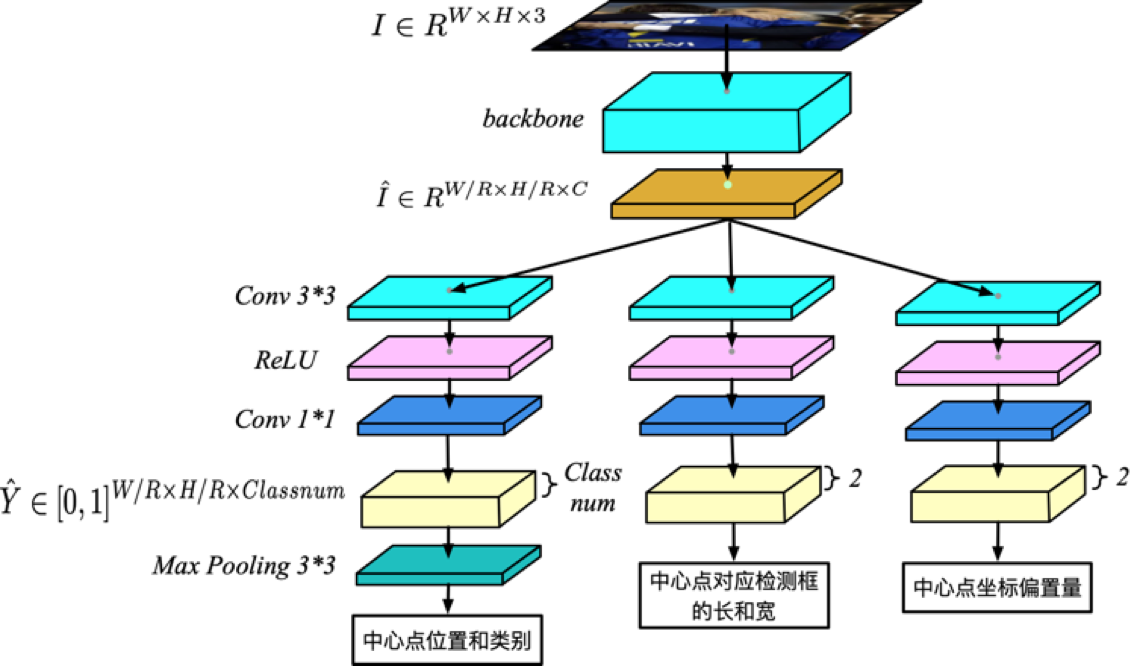
其中$I$为输入的图片,$\hat{I}$是backbone输出的特征图,$\hat{Y}$是输出类别分支的特征图,$\hat{Y}{x,y,c}=1$代表在$(x,y)$坐标处检测到类别C的物体,$\hat{Y}{x,y,c}=0$代表在$(x,y)$坐标处为背景
3、训练
在整个训练流程中,对于每个标签图中某一个C类,中心点的计算方式为$p=(\frac{x_1+x_2}{2},\frac{y_1+y_2}{2})$,对于下采样后的坐标,我们设为$\tilde{p}=\lfloor\frac{p}{R}\rfloor$,其中R是下采样因子,最终计算出来的中心点是对应低分辨率的中心点。
然后利用$Y\in[0,1]^{\frac{W}{R}\times \frac{H}{R}\times C}$来对图像进行标记,在下采样的图像中将GT中的点以$Y\in[0,1]^{\frac{W}{R}\times \frac{H}{R}\times C}$为中心,用一个高斯核$Y_{x,y,c}=exp(-\frac{(x-\tilde{p}_x)^2+(y-\tilde{p}_y)^2}{2\sigma_p^2})$来将关键点分布到特征图上,其中$\sigma_p$是一个与目标大小(也就是w和h)相关的标准差。如果某一个类的两个高斯分布发生重叠,直接取元素间的最大值。

